Among all the performance tools out there, Google’s Lighthouse is probably the most approachable. Since it ships with Google Chrome, it’s easy to run any site through it and get basic information regarding the performance of a page, and the 0-100 scoring system is simple to understand.
I credit Lighthouse as being a conversation starter for web performance, and I have had more people approach me about improving page performance due to their Lighthouse score than they have with any other tool.
The scenario
The scenario often plays out something like this:
Client: We really need to improve the performance of our site. It’s so slow.
Me: Ok. Thanks for bringing that to my attention. I’d love to help out. I am curious about what led you to believe your site was slow. Mind elaborating?
Client: Well, I ran our site through Lighthouse, and our score is only a 43.
Me: Ok. Is there a number you want to achieve?
Client: Yeah. We definitely want 100.
Me: 100, huh? Let me ask another question. Do you think that Google.com is a fast site?
Client: Oh, of course. One of the fastest.
Me: Would you be surprised to learn that Google doesn’t have a 100 for their Lighthouse score and neither does Amazon.com?
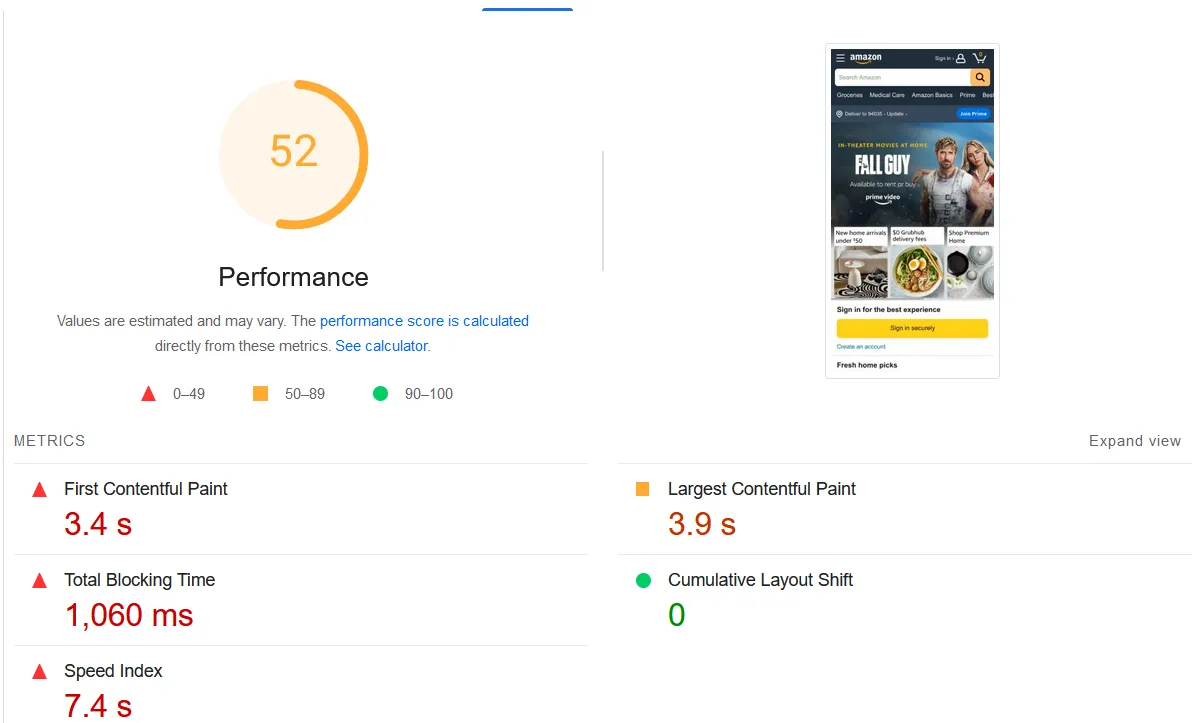
Client: Really? I had no idea.
Me: Yeah, I’ve seen Google’s score in the 70s before and Amazon’s in the 50s. Google also admits there’s variance in Lighthouse scores. If you’ve ever wondered why your scores might be different between subsequent runs or hard to compare with a colleague, that’s why. I’ll tell you what though…performance is an area of deep expertise for me, and I have a sophisticated toolkit for diagnosing issues. Would you mind if I did an audit of your site? I’ll come up with some recommendations that will improve performance overall. If there’s a correlation between a specific performance metric and a KPI, I can make sure to hone in on that.
Client: Sounds good.
Lighthouse scoring
When you run a Lighthouse test, you will get a score from 0-100. That score consists of five different metrics that each contribute a percentage to the overall score. The metrics are:
- Total Blocking Time (TBT)
- Speed Index
- Cumulative Layout Shift (CLS)
- First Contentful Paint (FCP)
- Largest Contentful Paint (LCP)
Further down in the results, there is a list of nearly 40 diagnostics. Those diagnostics can be valuable, but they can also be a bit overwhelming if you’re new to web performance optimization.
What’s wrong with it?
Unfortunately, with Lighthouse, the diagnostic information given isn’t clear if you don’t know where to start or how to make the numbers move. With so many diagnostics, identifying what should get addressed first is often difficult.
Not all advice is actionable
Some of the diagnostics might be beyond the control of a site owner, such as reducing the impact of third-party scripts. Other advice, like adding performance timing marks and measures, wouldn’t improve scores at all, as it’s a data collection strategy and not a remedy.
Even including Google Tag Manager with nothing other than the default Google Analytics tag contributes to TBT and can knock a few points off the overall Lighthouse score. If you have a site with ads that use header bidding, you will lose even more TBT points if those fire early and also lose some Speed Index points if the ad appears in the critical rendering path.
Everything you add to a site comes at a cost, and it’s up to you to decide if the things you are including are worth it.
Variability
Google acknowledges there is variability for scores on subsequent runs when nothing on the page has changed.
If you run Lighthouse locally, the results are impacted by browser cache, extensions, open tabs, running processes on your computer, and other factors. It’s difficult to compare results accurately with your colleagues when you are running your tests under different conditions than they are. You can run it in an incognito window to get around some of this, but for a publicly accessible URL, it’s best to run it through PageSpeed Insights, which is a consistent environment that can be used for comparison purposes.
However, there’s a difference in the simulated network throttling that Lighthouse applies versus packet-level throttling, the latter of which is much more representative of the actual conditions you’re trying to simulate. Tim Kadlec has a synopsis of the difference between throttling methods and the first-party source is in this document.
There are ways to do packet-level throttling in tests and disable Lighthouse’s simulated throttling, but that requires extra setup and removes much of the approachability of Lighthouse in the first place.
What do I do when I’m approached with a Lighthouse score?
Rather than fighting against Lighthouse usage, I’ll use the Lighthouse score as an opportunity to start a conversation about performance, gather information about why performance is important to a business, try to understand what numbers they’re trying to move and the motivation behind the ask, and learn about any established correlation that performance has to business objectives and revenue as I did above.
It’s worth noting that Google has designated three metrics as Core Web Vitals, but the Lighthouse score only factors in LCP and CLS. It does not use Interaction to Next Paint (INP) as part of its score. I’ll save any information about INP and CLS optimizations for another day. INP is a field-only metric, and Lighthouse uses Total Blocking Time (TBT) as a synthetic proxy metric for it. Today I want to focus on the FCP and LCP parts of the Lighthouse score.
Get a baseline
If you understand the metrics that are part of the Lighthouse score, it’s possible to improve them no matter what tool is used for the diagnosis because the strategy for implementation is independent of the tool used to diagnose the issue.
Before applying any performance corrections, I create a series of tests to establish a baseline for the starting point. I’ve written previously about performance gaps in the user experience, and this is a possible (and likely) avenue for optimization. For synthetic tests, my tool of choice is WebPageTest.
I like to look at both lab data from synthetic tests in addition to real user data from RUM tools, Treo, and the Chrome User Experience Report (CrUX). In the article linked above, the gap analysis serves as the framework for prioritizing performance fixes for the LCP.
To receive a rating of “Good,” the Core Web Vitals (CWV) metric needs to be under the designated threshold at the 75th percentile (p75). If you need a quick refresher on statistics, p75 means that if you took the data from a specific CWV metric and ordered them all from least to greatest, 75% of the data points would fall below the designated threshold and only 25% would be above it.
It’s possible that the field data and lab data will point to a larger problem with one of the other CWV metrics, but let’s assume for the sake of this article, that the largest problem is with LCP.
One of the most important things for making a site feel fast is to show content to the user as quickly as possible. There has been a burst of activity around this the last several years, with new and exciting APIs being added all the time. The list includes resource hints, 103 Early Hints, bf-cache, fetch priority, and most recently, the speculation rules API are now native parts of the web and being built into browsers. A large part of perceived performance means getting as much out of the browser’s way in the early parts of the page lifecycle and helping it prioritize the most important requests, and making sure the page has a stable UI and is quick to respond to user input throughout its lifecycle.
When someone says their site feels slow, a great place to look is at optimizing the LCP and its complementary metrics, Time to First Byte (TTFB) and FCP, if the baseline tests confirm it. These happen in a chronological order; TTFB will be first, FCP will happen second, and LCP will happen last.
TTFB
While a good TTFB doesn’t necessarily mean you will have a fast website, a bad TTFB almost certainly guarantees a slow one.
Harry Roberts
If there is a slow response between when the user navigates to a URL and when the server returns a response, I look at server performance, fix slow database queries, cache hit rates on the server, database, and CDN, and examine ways to make use of a CDN to get content closer to the user.
It also helps to reduce the size of network payloads. This means making sure text-based assets are being compressed, minified, and that everything is served with HTTP v2 or v3. Paul Calvano has a compression calculator so you can see how different types of compression reduce the size of a given URL, and Yellowlab can help identify server configuration issues, such as where HTTP/1.1 is being used.
FCP
Once content gets to the browser, it’s all about looking for efficiencies. You want to get the less important things out of the way of the important ones. This means looking at ways to reduce render blocking, prioritizing the load order of important elements, and deprioritizing, deferring, or lazy loading elements that aren’t in the critical rendering path.
Eliminate dead code, tree-shake dependencies, inline critical CSS, lazyload JS and CSS that aren’t needed for the initial render, and make sure there are no render-blocking third-party resources.
Third-party, render-blocking assets are a killer because at best, you are going to pay a latency penalty for the DNS lookup, connection time, and SSL negotiation, and at worst, they create a single point of failure if the third party is unavailable, making it appear as if your site is the one with the outage.
LCP
Once you do that, the page should show content to the user quicker. For LCP, get the element discovered early. If the LCP element is an image, make sure it’s an <img>, not lazyloaded, and not a CSS background, or inserted dynamically with JS. A smaller payload helps as well, and this can be achieved by making sure the image is properly sized, compressed, and in a modern format. Cloudinary has an image analysis tool that helps you see what kind of savings are on the table if the images are optimized.
If you have a text-based LCP element such as a page heading, you should make sure your text is visible while the page loads. Common causes that affect text visibility are web fonts that are loaded in a blocking fashion or A/B scripts that use an anti-flicker snippet.
Which part should get immediate attention?
To decide whether to focus on TTFB, FCP, or LCP, it helps to visualize the various parts of LCP or express them as a percentage to see where the most time is being spent.
Example 1
For the following data, it’s pretty easy to tell that there is a significant time between FCP and when LCP occurs.
The gap between FCP and LCP accounts for 54% of the total time, and therefore, focusing on the time between FCP and LCP makes the most sense in the short term. In this case, LCP was a background image that was improperly sized for the viewport. Using responsive images in a modern format and getting the LCP image into an <img> that is in the HTML source would be a big win.
Example 2
Here is another obvious one that screams for LCP optimization:
TTFB and FCP happen very quickly in this example, but it takes forever for the LCP to happen after that. The site is fully client-side rendered, which usually means opportunities to get the render to happen faster by code splitting and using dynamic imports, but in this case, the large JS bundle is being served uncompressed. Configuring Brotli or gzip would be a monumental improvement.
Example 3
Here’s another one:
The largest percentage of time in this case is spent on TTFB. In this case, the site is built with Django and hosted on AWS, but there is no CDN and the page cache reads from disk.
There is no memory-based cache store like Memcached or Redis, and the site could also benefit from a pre-cache strategy because the page-cache miss rate was quite high. The max-age directive for the HTML was only set to 30 minutes, and the site doesn’t get enough traffic to prime the cache for the critical pages on its own. Looking at the available RUM data also confirms that only 52% of people get a good TTFB.
The whole site is still being served with HTTP/1.1, which means that multiple connections need to be opened to get all the assets required for displaying the page, and that should be rolled up into the TTFB fixes as well.
Example 4
This is an interesting one because the FCP and LCP happen at the exact same time. Sometimes this is due to sites using an anti-flicker snippet on an A/B test that blocks rendering until the test has loaded. However, that’s not the reason for the long FCP for this site.
The reason FCP takes so long to happen for this site is twofold. The first reason is that the site’s main CSS file is being served unminified and with an inline source map on production, resulting in an 890KB file compressed and 3.2MB on disk.
The second item that impacts the slow FCP is that there are multiple blocking assets (CSS and JS) files in the <head> that are being served from third-party domains. Self-hosting these assets and using a prefetching mechanism like 103 Early Hints would help.
Again, the RUM data confirms that only 64.6% of page views receive a good FCP.
Example 5
This site is one I worked on extensively at my former employer. It is pretty fast, with all three CWV metrics classifying as “good” at p75 globally. Note that the LCP happens in 1.574s, and the LCP is in the good category for 88% of page views.
If I wanted to improve the performance further, there’s almost equal time spent on TTFB and FCP. Probably the easiest path would be to improve FCP by reducing the impact of render-blocking assets that appear in the <head>. There are some additional things that can be bundle split or removed that I never got around to before I left.
Sometimes, you need to critically assess business goals and find your sweet spot. Of course, there are some improvements that can be made, and that’s where things might get interesting. Having knowledge of the site, I know that the overwhelming majority of traffic for it comes from the US and Canada.
There are other countries that might be considered growth markets, such as Australia or the UK. Taking a look at performance in Australia, we get a different picture:
TTFB takes much longer in that situation. Even though the site is proxied with Cloudflare and pages are cached on the edge, there is still some reliance on location where the pages are cached. If that is far away from the Australian visitors, there’s latency involved, and if there is a total cache miss, the visitor has to connect to the origin server all the way in AWS us-east-1 region. The architecture described in An Informed Pre-caching Strategy for Large Sites was the proof of concept for how this could be solved.
Alternatively, this might point at other things to solve, such as the site’s heavy page weight due to display ads that use header bidding, or splitting up long tasks to reduce the TBT.
Example 6
In the example below, there’s a long FCP. This is due to blocking requests that appear in the head, and these numbers are an actual before benchmark from a site I’ve optimized in the past.
While there were some blocking requests on the site, there was also a third-party, render-blocking script that appeared in the <head>. If the domain for the script was ever unresponsive, that creates a single point of failure, and our time distribution would look like this:
My optimization efforts here were to get as much out of the browser’s way as I possibly could. I was able to remove the blocking script, and by the time I was finished, I got the FCP down to 1.6s at p75.
Wrapping up
Remember, the goal is not just to achieve a higher Lighthouse score but to create a smoother, faster, and more enjoyable user experience.
By directly trying to move a specific metric that makes up part of the Lighthouse score, you can be more focused in your performance optimization efforts. Using the baseline data can help ensure that efforts are directed where they will have the most impact.